Transformer 论文笔记:从 RNN 到 Attention Is All You Need
一、这篇笔记想解决什么问题
这篇文章是我对经典论文 《Attention Is All You Need》 的一份学习整理。相比直接逐段翻论文,我更想搞清楚几个最核心的问题:
- 为什么早期机器翻译模型主要依赖 RNN?
- 编码器-解码器架构解决了什么问题?
- 注意力机制到底在做什么?
- Transformer 为什么能在当时取代基于 RNN 的方法?
我的目标不是把论文一字不落复述出来,而是把这条技术演化路径理顺:从 RNN 的串行瓶颈,到注意力机制的引入,再到 Transformer 完全抛弃 RNN,只保留注意力机制。
二、论文背景:机器翻译为什么重要
机器翻译的任务,是把一种语言中的一段文本转换成另一种语言中的文本。这个任务的难点在于:翻译通常没有唯一标准答案,因此很难像分类任务那样直接用准确率评价。于是,在机器翻译中常用的一种指标是 BLEU Score,它通过比较模型输出和参考翻译之间的重合程度来评估翻译质量。
在 Transformer 出现之前,序列建模领域最核心的模型仍然是 RNN(循环神经网络) 及其变种,例如 LSTM、GRU。它们在翻译、语言建模等任务上取得过非常强的结果。
但问题也很明显:RNN 的计算天生依赖前一个时刻的隐藏状态,因此必须串行执行。
这件事在训练时会带来两个后果:
- 序列越长,并行效率越差;
- 长距离依赖更难建模,训练成本也更高。
所以,Transformer 这篇论文其实是在回答一个非常直接的问题:
如果注意力机制已经足够强了,为什么还要把它绑在 RNN 上?
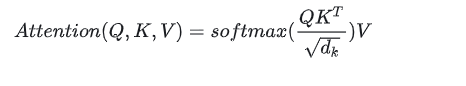
三、从 RNN 到编码器-解码器
3.1 RNN 为什么曾经好用
最基础的 RNN 适合处理“输入输出等长”的任务。模型逐个读入 token,并持续维护一个隐藏状态,再基于当前状态输出结果。
但机器翻译通常不是等长映射:
- 输入一句中文,输出一句英文;
- 输入长度和输出长度通常不同;
- 句子结构也可能完全不同。
3.2 编码器-解码器解决了什么问题
于是出现了 编码器-解码器(Encoder-Decoder) 架构:
- 编码器负责读入输入序列;
- 解码器负责逐步生成输出序列;
- 两者通过一个中间表示来交换信息。
这个设计解决了“输入输出长度不一致”的问题,但又引入了新的限制。
3.3 只靠一个中间状态,信息容量不够
如果输入句子很长,那么把全部语义都压缩到一个固定长度的向量里,信息损失会非常严重。于是,后续工作开始尝试让解码器不要只看一个中间状态,而是动态地从编码器输出中取信息。
这就是注意力机制出现的背景。
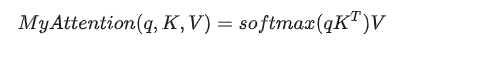
四、注意力机制到底是什么
如果只看名字,“注意力”其实很容易让人误解。更直观地理解,它更像一种:
全局信息查询机制。
也就是:
- 当前这个位置想得到什么信息?
- 它应该去看输入序列里的哪些部分?
- 每一部分应该给多大权重?
4.1 一个直观理解
可以把它想成数据库查询:
Query:你当前要问什么;Key:每条记录的索引特征;Value:每条记录真正携带的信息。
模型会做的事是:
- 用 Query 和每个 Key 计算相似度;
- 把相似度归一化成权重;
- 用这些权重对所有 Value 做加权求和;
- 得到这次“查询”的结果。
这样一来,模型就不再是机械地依赖“上一个状态”,而是可以在整个输入序列里有选择地查找相关信息。
4.2 我自己的理解
我觉得“注意力”这个名字本身有点抽象。对初学者来说,把它理解成“全局检索 + 加权汇总”会更容易。
也就是说,模型不是死记当前位置前后的内容,而是在问:
- 我现在最需要什么?
- 哪些位置和我最相关?
- 我该从哪里拿信息?
当你把它理解成一种“动态查资料”的机制后,很多公式的意义就清楚了。
五、Scaled Dot-Product Attention
Transformer 中使用的注意力形式叫做:
Scaled Dot-Product Attention
公式写作:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
这里:
Q是 QueryK是 KeyV是 Valued_k是 key/query 向量维度
5.1 为什么要除以 sqrt(d_k)
原因是:
- 向量维度越高,点积的数值可能越大;
- 数值太大时,softmax 会进入梯度很小的区域;
- 训练会变慢、变不稳定。
所以这个放缩项,本质上是为了让训练更稳定。
5.2 这一步真正干了什么
从直观角度看,这一步就是:
- 先算“当前 query 和所有 key 谁更像”;
- 再把“像”的程度变成权重;
- 最后按权重汇总 value。
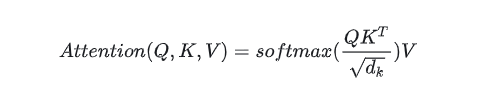
六、自注意力:让每个词都能看见整句话
Transformer 里最核心的注意力形式是 Self-Attention(自注意力)。
它的作用是:
让句子里的每个 token 都可以和其他 token 建立联系,从而得到一个更有上下文意义的表示。
6.1 为什么它重要
如果一句话里某个词有多种可能含义,那么它真正表示什么,往往要看上下文。自注意力的意义就在于:
- 当前词可以“查看”整句话里的其他词;
- 根据相关程度决定关注哪些信息;
- 最终得到带上下文信息的新表示。
这也是为什么 Transformer 特别擅长建模长距离依赖: 它不需要像 RNN 一样一层层传递,任意两个位置都可以直接建立关系。
6.2 我的理解
我觉得自注意力真正强的地方,不在“数学形式很酷”,而在于它改变了序列建模的组织方式。
在 RNN 里,信息是沿时间步传的; 在自注意力里,信息是全局直连的。
这两者的建模思想差别非常大。




七、多头注意力:不只看一种关系
如果只做一次注意力计算,模型学到的相关性可能比较单一。于是论文进一步提出了 Multi-Head Attention(多头注意力)。
它的核心思想是:
- 把特征拆成多个子空间;
- 在不同子空间里分别做注意力;
- 最后再把结果拼接起来。
这样做的好处是:
- 一个头可以关注句法关系;
- 一个头可以关注语义相似性;
- 一个头可以关注位置相关的信息;
- 不同头可以学到不同类型的依赖模式。
所以,多头注意力本质上是在提升模型表达能力,而不是单纯增加计算量。

八、Transformer 整体架构怎么理解
在理解了注意力之后,再回头看 Transformer 的结构就清楚很多了。
8.1 编码器部分
编码器每一层主要包含两部分:
- 多头自注意力
- 前馈网络(Feed Forward Network)
此外,每个子层外面还有:
- 残差连接(Residual Connection)
- Layer Normalization(归一化)
8.2 解码器部分
解码器结构和编码器类似,但多了一层:
- Masked Multi-Head Self-Attention
为什么要 mask?
因为在生成第 t 个 token 时,模型不应该偷看未来位置的信息。也就是说:
- 当前时刻只能利用当前位置之前已经生成的内容;
- 未来 token 必须被遮住。
这就是解码器里 masked 的意义。
解码器后面还有一层“交叉注意力”:
- Query 来自解码器当前状态;
- Key 和 Value 来自编码器输出;
它的作用是:让输出序列在生成每一个 token 时,都能回头去参考输入序列中最相关的部分。

8.3 Add & Norm 和 Feed Forward 是什么
前馈网络(Feed Forward)其实就是一个全连接网络,负责对每个位置的表示再做非线性变换。
Add & Norm 可以理解成:
- 先做残差连接,保留原始信息;
- 再做归一化,让训练更稳定。
这两个模块看起来不起眼,但它们对深层网络训练非常重要。
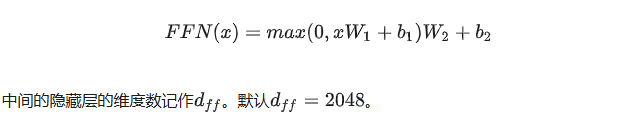
8.4 我的理解
我觉得 Transformer 的整体架构可以分成三层来看:
- 注意力层:负责找关系
- 前馈层:负责做特征变换
- 残差与归一化:负责让训练稳住
这样一拆开,整套结构就没那么神秘了。
九、为什么 Transformer 能取代 RNN
结合前面的内容,可以把 Transformer 的优势概括成三点:
9.1 并行性更强
RNN 必须一步一步算,而 Transformer 的自注意力可以在训练时并行处理整个序列。
9.2 更容易建模长距离依赖
RNN 中远距离信息要经过很多步才能传递;Transformer 中任意位置可以直接建立联系。
9.3 注意力机制被放到核心位置
以前很多模型是“RNN + attention”,而 Transformer 则是:
直接把注意力机制当作主干,而不是辅助手段。
这也是这篇论文最革命性的地方。
十、我对这篇论文的理解
读完之后,我觉得这篇论文最重要的不只是提出了一个新模型,而是完成了一次非常彻底的结构替换:
- 不再把序列建模建立在循环结构上;
- 把“依赖建模”的核心任务交给注意力机制;
- 同时又兼顾了训练效率和性能。
从今天往回看,Transformer 已经成了大模型时代最核心的基础架构之一。但如果放回论文当时的背景,它真正厉害的地方在于:
作者不是在原有 RNN 框架上继续修修补补,而是直接换了一条路。
这也是为什么这篇论文直到今天依然值得反复阅读。
十一、这篇笔记帮助我理清了什么
整理完之后,我觉得自己至少把下面这条逻辑链串起来了:
- RNN 能做序列建模,但训练串行、长距离依赖难处理;
- 编码器-解码器解决了输入输出不等长的问题;
- 注意力机制改善了信息传递方式;
- Transformer 进一步抛弃 RNN,把注意力机制变成主角;
- 多头注意力、自注意力、masked attention 一起构成了完整架构。
如果后面继续深入,我觉得值得接着看的是:
- 位置编码(Positional Encoding)到底是怎么设计的;
- Transformer 的训练细节,例如 label smoothing、learning rate schedule;
- Transformer 在视觉、多模态和大语言模型中的后续演化。
十二、总结
如果只用一句话概括这篇论文,我会写成:
Transformer 的核心贡献,不只是提出了注意力机制,而是证明了“只靠注意力机制,也能搭出一个强大的序列建模系统”。
这也是它能成为后续大模型基础的根本原因。