CLIP 论文阅读笔记
围绕 CLIP 的训练目标、双编码器结构、零样本迁移能力、实验结论与局限性的系统整理。
这篇内容基于原始 Notion 导出整理,并结合 CLIP 论文原文与 OpenAI 官方介绍做了补充,尽量保留原始笔记里“图解 + 解释”的阅读方式。
一、这篇论文在解决什么问题
传统视觉模型大多依赖人工标注数据集训练,比如 ImageNet 这种“先定义类别、再人工标数据”的范式。它的问题很明显:
- 标注成本高
- 类别空间是预先固定的
- 一旦换任务,往往还要重新收集数据、重新训练分类头
CLIP(Contrastive Language-Image Pre-training)想做的事情更直接:不用只盯着封闭标签集,而是直接从互联网上大规模图文对中学习视觉概念。论文的核心设定是:
- 用一个图像编码器提取图像特征
- 用一个文本编码器提取文本特征
- 训练模型判断“哪段文本和哪张图是匹配的”
这样学到的就不是某个固定任务的分类器,而是一套更通用的跨模态表示。论文中提到,他们使用了 4 亿对图文数据进行训练;训练完成后,模型可以直接通过自然语言提示完成下游任务的零样本迁移(zero-shot transfer)。
从论文摘要来看,CLIP 的关键贡献不只是“多模态”,而是证明了:仅靠大规模自然语言监督,也能学到具有很强迁移能力的视觉表示。作者在 30 多个视觉数据集上做了评估,涵盖 OCR、动作识别、地理定位、细粒度分类等任务;其中一个最经典的结果是:CLIP 在 ImageNet 的 zero-shot 设置下,达到了原始 ResNet-50 的准确率水平,但没有用那 128 万张标注训练图像。
二、CLIP 的核心思路
1. 直观理解
一句话说,CLIP 的目标就是:
把图像和文本映射到同一个语义空间里,让匹配的图文距离更近,不匹配的图文距离更远。
下面这张图就是最直观的结构示意:
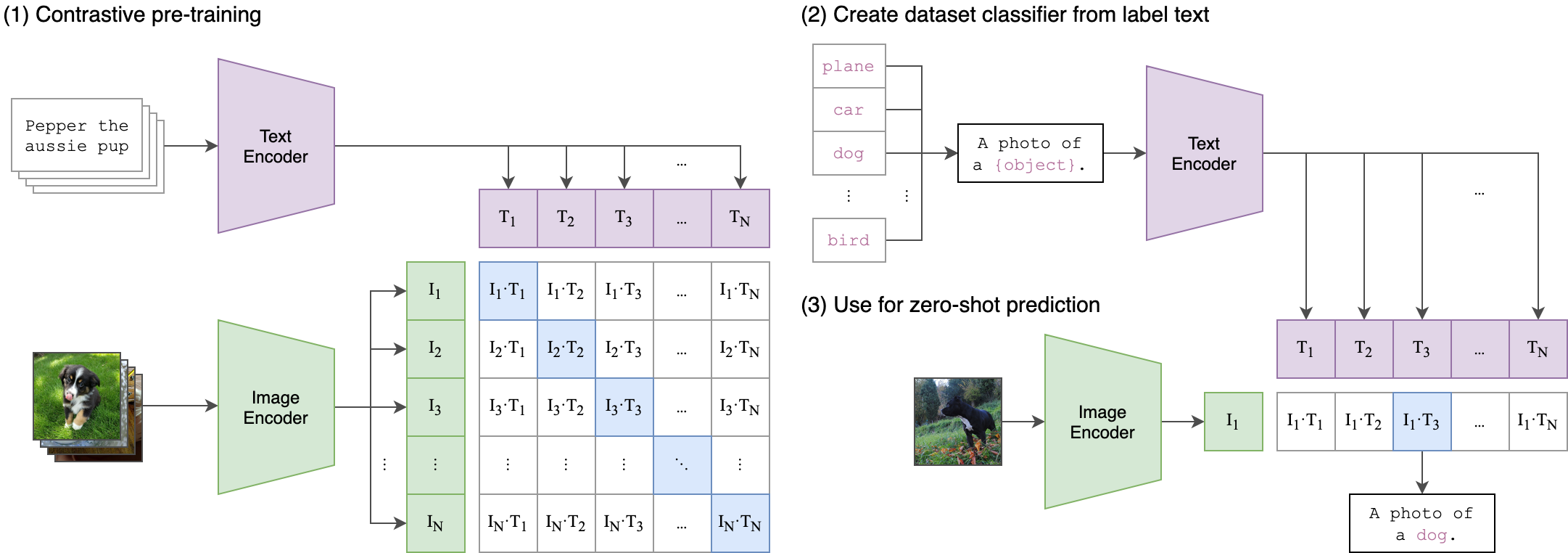
CLIP 通过学习图像和文本的 embedding 来完成跨模态对齐:
- 匹配的图文对,相似度高
- 不匹配的图文对,相似度低
这其实就是典型的**对比学习(contrastive learning)**思路,只不过这里对比的对象不再是两张图,而是“图像”和“文本”这两种模态。
2. 为什么这件事重要
CLIP 重要,不只是因为它“能看图配文”,而是因为它把传统视觉模型的监督方式换掉了:
- 打破固定标签限制:不需要把世界先压缩成 1000 个类别
- 自然语言本身就是监督信号:文本比标签 richer,包含上下文和语义关系
- 更适合开放世界任务:新类别、新描述可以直接通过 prompt 指定
- 迁移更方便:很多任务不需要重新训练,只需要改文本提示
OpenAI 官方介绍里特别强调了这一点:传统模型往往在 benchmark 上很好,但换到真实世界环境就会掉得厉害;而 CLIP 由于不是围着某个特定 benchmark 的训练集优化,zero-shot 评估反而更能反映它在真实场景中的泛化能力。
三、模型结构:双编码器
CLIP 的结构非常简洁,本质上是一个双塔 / 双流编码器(two-stream architecture):
| 模块 | 作用 | 典型结构 |
|---|---|---|
| 图像编码器 | 把图片编码成向量 | ResNet 或 Vision Transformer |
| 文本编码器 | 把文本编码成向量 | Transformer |
1. 文本编码器
原始笔记里这部分图对理解结构很有帮助,这里保留下来:
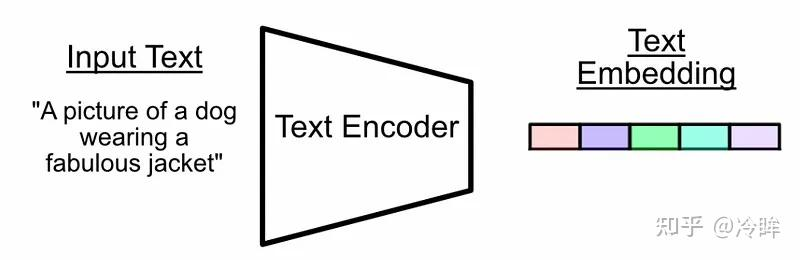
CLIP 的文本编码器是一个标准 Transformer 编码器,可以把输入文本序列编码成一个全局语义向量。直观上可以理解成:
- 输入一句文本,例如
a photo of a dog - Transformer 对整句进行上下文建模
- 最终提取一个向量,作为这句话的语义表示
这一步很关键,因为 CLIP 不再把类别看作离散 id,而是把类别写成自然语言短句。这样做带来的直接好处是:分类器不再是参数表,而是由文本编码器动态生成。
2. 图像编码器
图像端也同样会被编码成向量:
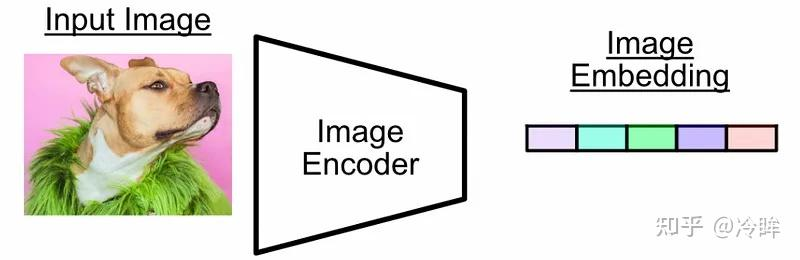
论文中图像编码器尝试了不同架构,主要包括:
- ResNet 系列:更接近当时主流 CNN 路线
- Vision Transformer(ViT):后续也成为非常重要的配置
无论底层结构是什么,图像端的目标都是一样的:把输入图像压缩成一个向量表示,再与文本向量在同一空间里进行比较。
3. 为什么要用双编码器
双编码器结构有一个很现实的优点:推理效率高。
因为图像和文本可以分别编码,所以:
- 候选文本类别可以提前算好 embedding
- 新图像进来时,只需要算一次图像向量
- 然后和所有文本向量做相似度比较即可
这使得 CLIP 很适合做:
- 零样本分类
- 文本检索图像
- 图像检索文本
- 作为生成模型或检索系统的语义前端
四、训练目标:CLIP 到底怎么学
1. 批量内匹配
CLIP 的训练非常朴素但有效。假设一个 batch 里有 N 张图片和对应的 N 段文本,那么模型会:
- 分别提取所有图像向量和文本向量
- 计算两两之间的相似度,得到一个
N × N的相似度矩阵 - 希望对角线上的配对(真实匹配)分数高
- 非对角线上的错误配对分数低
这样训练之后,模型就学会了“哪张图该和哪段文本靠近”。
2. 本质是对比学习
它背后的思想可以看作是 cross-modal 版本的对比学习:
- 正样本:匹配图文对
- 负样本:不匹配图文对
- 优化目标:最大化正样本相似度,最小化负样本相似度
很多介绍会把它概括为 InfoNCE 风格目标,这样理解是没问题的。更直观地说,也可以把 CLIP 训练理解成一种“图文版的大规模检索预训练”。
3. 和传统分类训练的区别
传统分类模型学的是:
输入图片 → 预测预设类别 id
而 CLIP 学的是:
输入图片和文本 → 判断二者是否语义匹配
这个差别非常重要,因为后者天然更开放:
- 类别名称可以换
- 任务描述可以换
- 甚至可以不是“类别名”,而是一句更完整的 prompt
这也是为什么 prompt engineering 在 CLIP 里会直接影响效果。
五、Zero-Shot 推理为什么成立
CLIP 最有代表性的能力,就是不微调直接做分类。
典型流程如下:
- 先把类别写成若干文本模板,例如:
a photo of a doga photo of a cata photo of a car
- 用文本编码器得到这些候选类别的向量
- 用图像编码器得到测试图像的向量
- 计算图像向量与所有文本向量的相似度
- 相似度最高的文本就是预测结果
这里的关键点在于:分类头不是额外训练出来的,而是由文本 prompt 直接定义出来的。
所以从某种意义上说,CLIP 把“分类器权重”替换成了“语言描述”。这也是它后来对大量 vision-language work 和生成式 AI 非常重要的原因。
一个简单示例
import torch
from PIL import Image
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open("dog.jpg")
labels = ["a photo of a cat", "a photo of a dog", "a photo of a car"]
inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model(**inputs)
probs = outputs.logits_per_image.softmax(dim=1)
print(probs)这个例子虽然简单,但已经体现了 CLIP 的典型用法:同一个模型,不改参数,只改文本候选,就能切换任务定义。
六、论文里最值得记住的实验结论
如果只是把 CLIP 理解成“一个图文对比学习模型”,其实还不够。真正让它出圈的,是它的实验结果说明这套方法确实有广泛迁移能力。
从论文摘要和 OpenAI 的官方介绍里,至少有几点值得记:
1. 大规模自然语言监督是有效的
作者证明了:仅通过“预测哪段文本对应哪张图”这一简单预训练任务,就能从头学出很强的视觉表示。这一点本身就很重要,因为它说明自然语言监督不只是辅助信息,而是可以成为主监督来源。
2. Zero-shot 能和监督学习 baseline 竞争
论文中最常被引用的结果是:
- 在 ImageNet 的 zero-shot 设置下,CLIP 达到了原始 ResNet-50 的准确率水平
- 而且没有使用 ImageNet 的 128 万张标注训练图像
这个结果的象征意义非常强:它说明“语言监督 + 大规模预训练”这条路线,已经足以和经典监督学习管线正面对比。
3. 泛化能力比只盯 benchmark 的模型更真实
OpenAI 官方还提出了一个很有意思的观察:
- 传统模型在 benchmark 上可能表现很好
- 但这未必等于它在真实世界里同样稳
- 因为很多模型本质上是在“针对考试刷题”
而 CLIP 的 zero-shot 评估不依赖目标数据集的训练集,因此更能反映真实泛化能力。官方还提到:如果在 CLIP 特征上再额外训练一个 ImageNet 线性分类器,ImageNet 测试集精度会继续提高,但对其他鲁棒性数据集的平均收益并不明显。这从反面说明,zero-shot 评价更接近通用表示能力,而不是单一 benchmark 拟合能力。
七、CLIP 的典型应用场景
1. 零样本分类
这是最直接的应用:给定若干文本候选,直接完成分类,不需要针对新任务重新训练模型。
2. 语义检索
因为图文在同一个空间里,可以自然支持:
- 文本检索图像
- 图像检索文本
比如输入 two dogs running in snow,系统可以直接去图库里找最相关的图片,而不是依赖手工标签或 metadata。
3. 生成模型中的语义评估或引导
CLIP 后来在生成式 AI 里也非常重要,例如:
- 评估生成图像与 prompt 的一致性(CLIP Score)
- 作为扩散模型或图像生成系统中的语义对齐模块
4. 数据清洗与弱监督过滤
如果一个系统需要处理海量图文数据,CLIP 还可以用来判断图文是否匹配,从而过滤低质量样本。这种能力在后续更大规模多模态数据集构建中很有价值。
八、局限性与需要注意的问题
CLIP 很强,但它绝不是“万能视觉模型”。
1. 计数和复杂推理仍然弱
论文和后续经验都表明,CLIP 在下面这些问题上往往不稳定:
- 精确计数
- 复杂空间关系判断
- 多步逻辑推理
它擅长的是语义匹配,不擅长需要严谨结构推理的任务。
2. 细粒度识别不一定占优
当任务要求非常精细地区分相似类别时,例如:
- 极相近车型
- 花卉细粒度品种
- 工业零件中外观差异很小的类别
CLIP 往往不如专门用该领域标注数据训练的监督模型。
3. 对文本和数据分布很敏感
它的 zero-shot 表现会明显受 prompt 模板影响,这意味着:
- 文本写法会影响结果
- 类别描述方式会影响结果
- 数据集中常见表达和真实应用表达不一致时,效果可能波动
4. 数据偏见问题
CLIP 使用互联网图文数据训练,这天然可能带来:
- 性别偏见
- 种族偏见
- 文化语境偏差
- 不受控噪声
所以在真实系统里,尤其是涉及敏感类别判断时,要谨慎使用。
九、这篇论文为什么重要
如果从方法演进的角度看,CLIP 的意义至少有三层:
- 它证明了自然语言可以成为强监督信号,而不只是辅助标签。
- 它把视觉分类从封闭标签空间推进到了开放文本空间。
- 它为后来的 vision-language model、图像生成模型和多模态基础模型打了很重要的地基。
今天再回头看,CLIP 的结构其实不复杂,甚至可以说很“朴素”。但正是这种朴素结构 + 大规模数据 + 合适训练目标的组合,让它成为多模态领域一个非常关键的起点。
十、学习资源
- 原始论文:https://arxiv.org/abs/2103.00020
- PMLR 版本:https://proceedings.mlr.press/v139/radford21a.html
- OpenAI 官方介绍:https://openai.com/index/clip/
- 官方代码:https://github.com/openai/CLIP
- Hugging Face 文档:https://huggingface.co/docs/transformers/model_doc/clip
参考说明
本文补充内容主要参考:
- Radford et al., Learning Transferable Visual Models From Natural Language Supervision, ICML 2021 / PMLR 139
- OpenAI 官方页面 CLIP: Connecting text and images
其中用到的关键信息包括:
- 4 亿图文对预训练
- 在 30+ 数据集上的迁移评估
- ImageNet zero-shot 达到原始 ResNet-50 水平
- zero-shot 评估更能反映真实泛化能力这一讨论